Azure SQL Database は、生成 AI の活用に向けて進化しており、その中でも注目すべきは、ベクトル型データのサポートと、それを活用した RAG(Retrieval-Augmented Generation)の構成である。これにより、大規模言語モデル(LLM)をさらに効率的に利用できるため、サンプルコードを利用して検証した。
ベクトル 型データとは
ベクトル 型データはデータの個々の要素を数値で表し、それらが相互に関連する方法を示すデータ構造である。類似性検索や機械学習において使用されており、Azure SQL Database では、この ベクトルデータを効率的に格納するため、ベクトル 型データタイプを提供している。データは最適化されたバイナリ形式で格納され、必要に応じて JSON 配列としてアクセス可能である。 このように効率的にベクトルデータを管理することで、SQLクエリを使用して迅速かつ簡単に類似性検索を実行することが可能になる。
RAG とは
RAG は、外部データソースから検索した情報を使用して、大規模言語モデル(LLM)がユーザーのプロンプトに対してより豊富な応答を生成できる技術である。これは、ユーザーがプロンプトに追加のコンテキストを提供することにより、LLM がより正確で高品質な応答を生成することを可能にする。 Azure SQL Database のベクトル データ型を活用すると、RAG システムのデータ検索をさらに効率化できる。具体的には、ベクトルデータを効率的に格納し、類似性検索を迅速に行うことで、必要な情報を取得しやすくなる。
Azure SQL Database で RAG が構築できるメリット
Azure SQL Database で ベクトル 型データを使用することによる利点は以下が考えられる
- 効率的なデータ管理とクエリの速度向上: ベクトルデータを最適化されたバイナリ形式で格納することにより、データベース内での操作が効率的に行われ、クエリの応答時間が短縮される。
- 統合データベースシステムの利便性: Azure SQL Database では、ベクトルデータと運用データを同じデータベース内で管理できるため、別の検索システムが不要になる。Azure Cosmos DB をベクトルストアとして、Azure AI Search を検索システムとして用いるような RAG の構成が広く知られていたが、Azure SQL Database のベクトルサポートにより、データベースに存在するデータをベクトル化する敷居が下がったと考えられる。
- 高度なクエリ処理: Azure SQL の高度なクエリオプティマイザを利用することで、類似性検索、JOIN や集約などの操作を効率的に行うことができる。これにより、運用データとベクトル化されたデータを組み合わせた複雑なクエリが実行可能になる。
Announcing EAP for Vector Support in Azure SQL Database
サンプルコードの検証
SQL DB の RAG の構築に関して、以下のサンプルを利用して検証した。こちらに関しては、wikipedia のデータをデータベースに取り込み、埋め込みを生成しベクトル検索を実施する。
Samples on how to use Azure SQL database with Azure OpenAI
ベクトル 型、ベクトル検索に関しては、特に Azure SQL Database で追加の設定なく利用することができる。 そのため、既存のデータベースでも埋め込みを生成し、ベクトル検索させることが可能である。 事前準備として、以下などを参考に Azure SQL Database をデプロイする。
クイックスタート: 単一データベースを作成する - Azure SQL Database
以下のスクリプトを 0 から 5 まで実行していく。
https://github.com/Azure-Samples/azure-sql-db-openai/tree/main/vector-embeddings
- ストレージアカウントの設定
リポジトリからも確認できるが、以下から wikipedia の csv をダウンロードしておき、ストレージアカウントに格納しておく。
https://cdn.openai.com/API/examples/data/vector_database_wikipedia_articles_embedded.zip
スクリプトにおいて、格納したストレージアカウント名に変更し、Shared Access Signature も合わせて記載する。SAS は以下で生成することが可能である。
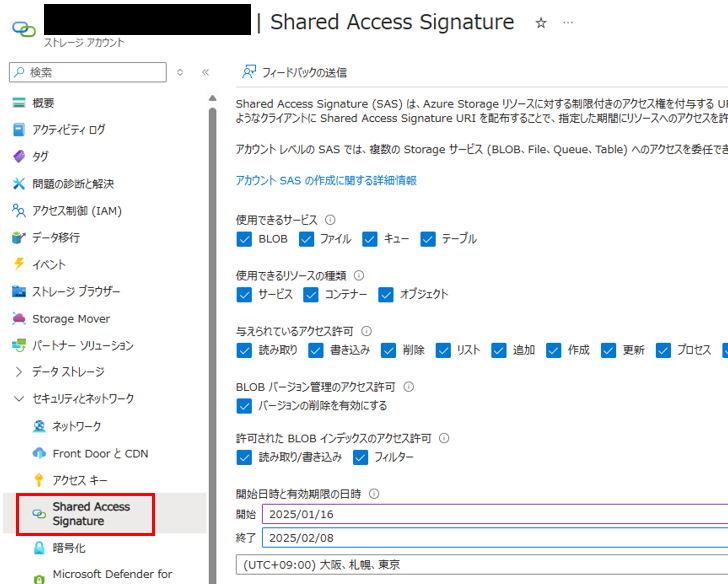
サンプルスクリプトでは、コンテナ名 playground にデータを格納しているため、コンテナ playground を作成しておく。
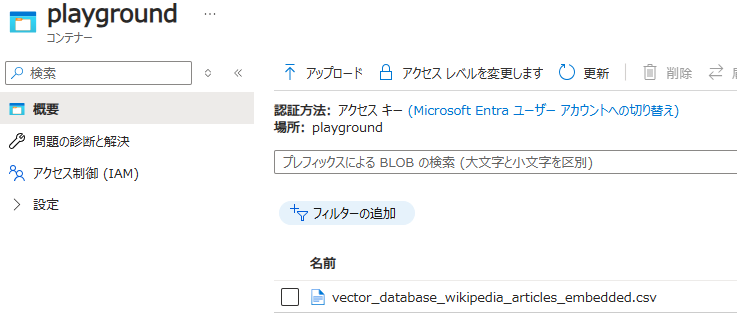
-
wiki データの読み込み
csv が約 1.6 GB であるため、ストレージアカウントから csv を読み込むのに、サービスレベルによっては時間を要する。 -
テーブルの更新
今回の csv では、サンプルのため既に title, text の埋め込みが生成されている。そのため、テーブルに読み込んだ時点で埋め込みは存在しているが、ベクトル 型として利用するため型変換を実施している。 実際に構築する場合においては、以下の手順を参考に、対象データの埋め込みを生成する必要がある。 csv から入力したデータは、テーブル wikipedia_articles_embeddings に格納され、ベクトル化された title と text が格納されていることがわかる。

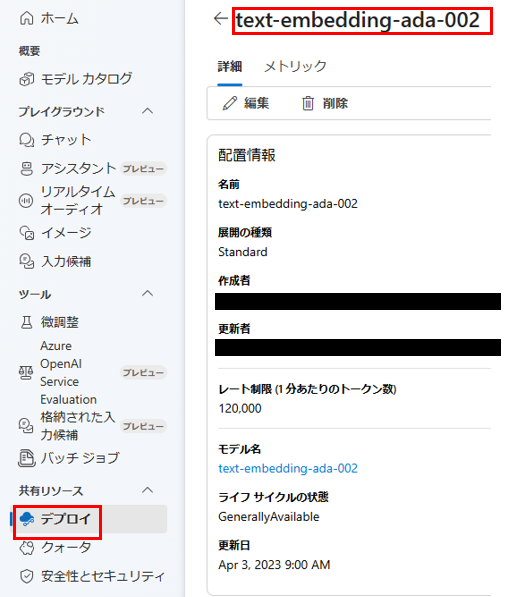
- OpneAI に対するクレデンシャルの生成
OPENAI を call するためのクレデンシャルを作成している。埋め込みを生成する LLM を利用するため、ここでは Azure OpenAI の text-embedding-ada-002 をデプロイした。
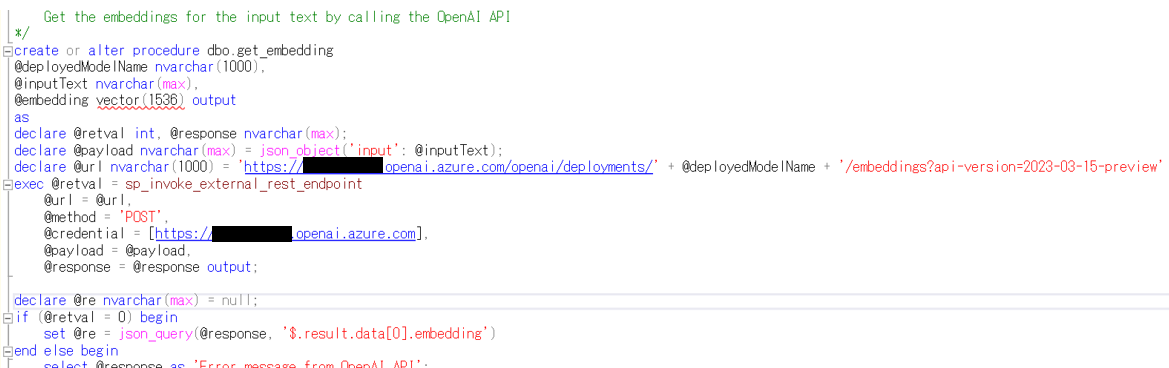
- OpenAI を call するストアドプロシージャの作成
sp_invoke_external_rest_endpoint を利用することで、Azure SQL Database から REST エンドポイントを呼び出すことが可能でき、Azure OpenAI をはじめとする LLM を呼び出すことができる。sp_invoke_external_rest_endpoint を利用するストアドプロシージャを作成しておく。
sp_invoke_external_rest_endpoint (Transact-SQL)
- ベクトル検索
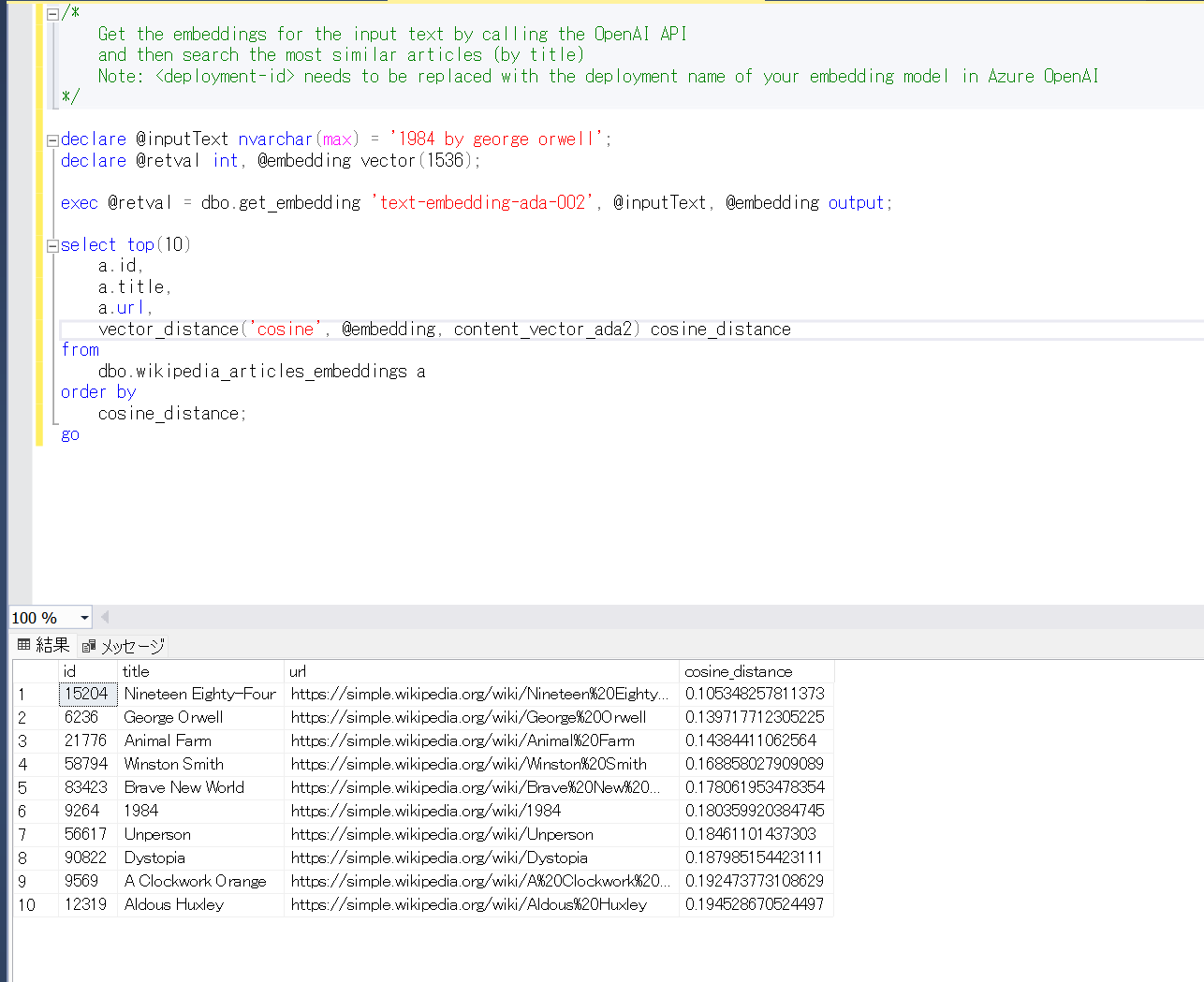
入力されたプロンプト inputText に対して、手順 4 で作成したストアドプロシージャを実行し埋め込みを作成している。これにより、ベクトル同士の比較をすることができ、意味を考慮した比較が可能になる。vector_distance(‘cosine’, vector1, vector2) でコサイン類似度によるベクトル同士の類似度を比較する。
VECTOR_DISTANCE (Transact-SQL) (プレビュー)
入力プロンプトを 1984 by george orwell として、vector_distance の比較対象を content_vector_ada2 にすると、最も近しいものが Nineteen Eighty-Four のページとなる。文字列の単純な比較であれば、1984 という数字とアルファベットで表記されたものを結びつけることが困難である。しかし、ベクトル 化して比較することで、検索することが可能となる。加えて、Winston Smith のページが上位に来ているが、これは 1984 の主人公である。
まとめ
Azure SQL Database にて、ベクトルデータがサポートされていることによって、生成 AI の利用を加速させることができる。 これにより、従来のデータを利用し、検索システムを用いずデータベースの組み込みの機能を利用した RAG を実装できることを確認した。